
Amna is local-first software. Meaning, data that you put into Amna is stored on your machine as the first stop.
It relies on the cloud for accessory functions like sharing tasks and syncing, but a constant connection is not necessary to continue working.
Using my Amna at Waikiki Beach
Power to the consumer.
Local First Challenges
I’d argue that it’s harder to build local-first today than it is to create consumer software in the cloud.
A lot of that has to do with the expectations of consumers:
-
Available on mobile and desktop
-
All connected devices do not have to be online to get changes
-
Work needs to be shared to other people
Most cloud solutions are well established, and offer amazing libraries to do a lot of heavy lifiting. You would have to worry very little about how data is synchronized.
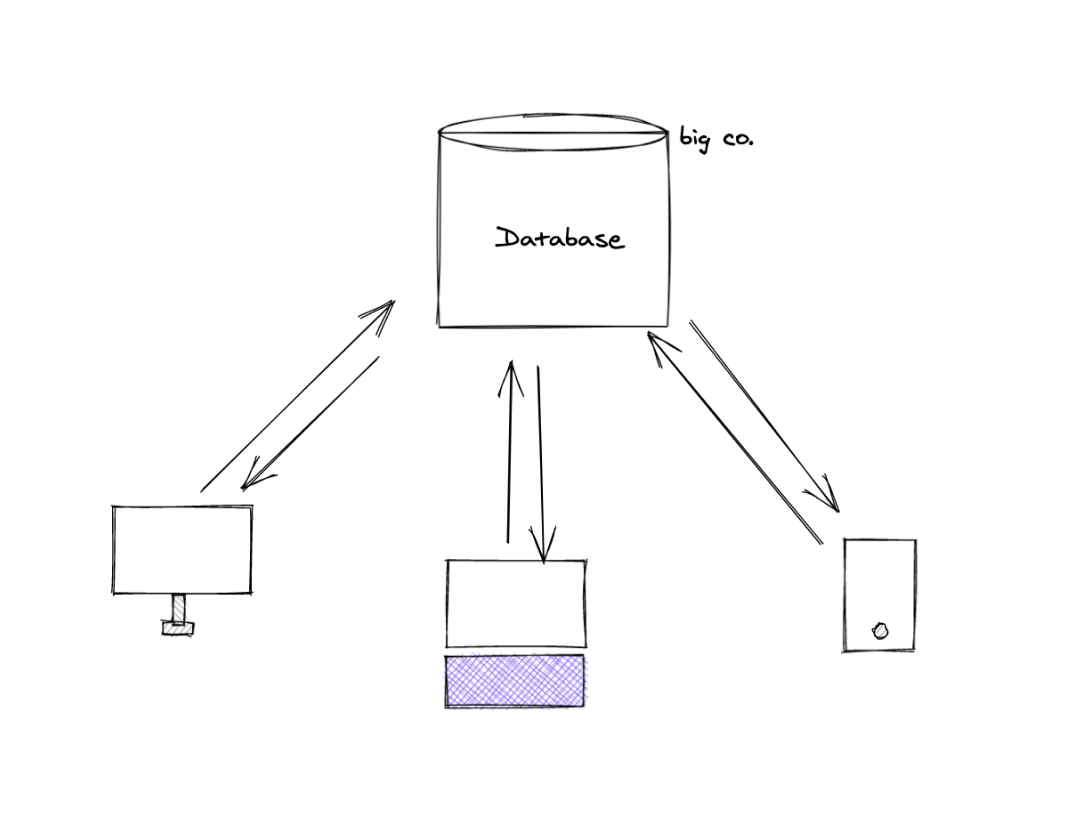
Traditional Cloud App Model
Of course, the cost is data and privacy. After all, it’s a centralized repo with all of your information alongside your friends. The term agreement offers only two options: yes or quit.
Amna Graph Data
Data in Amna is represented as a graph. From trial and error, we realized that any other structures were far too rigid. Tasks are not linear, and neither is infomation. Things can live in multiple places, and multiple bits can support different tasks.
Your data sits in a file called graph.json and exportable from the settings tab.
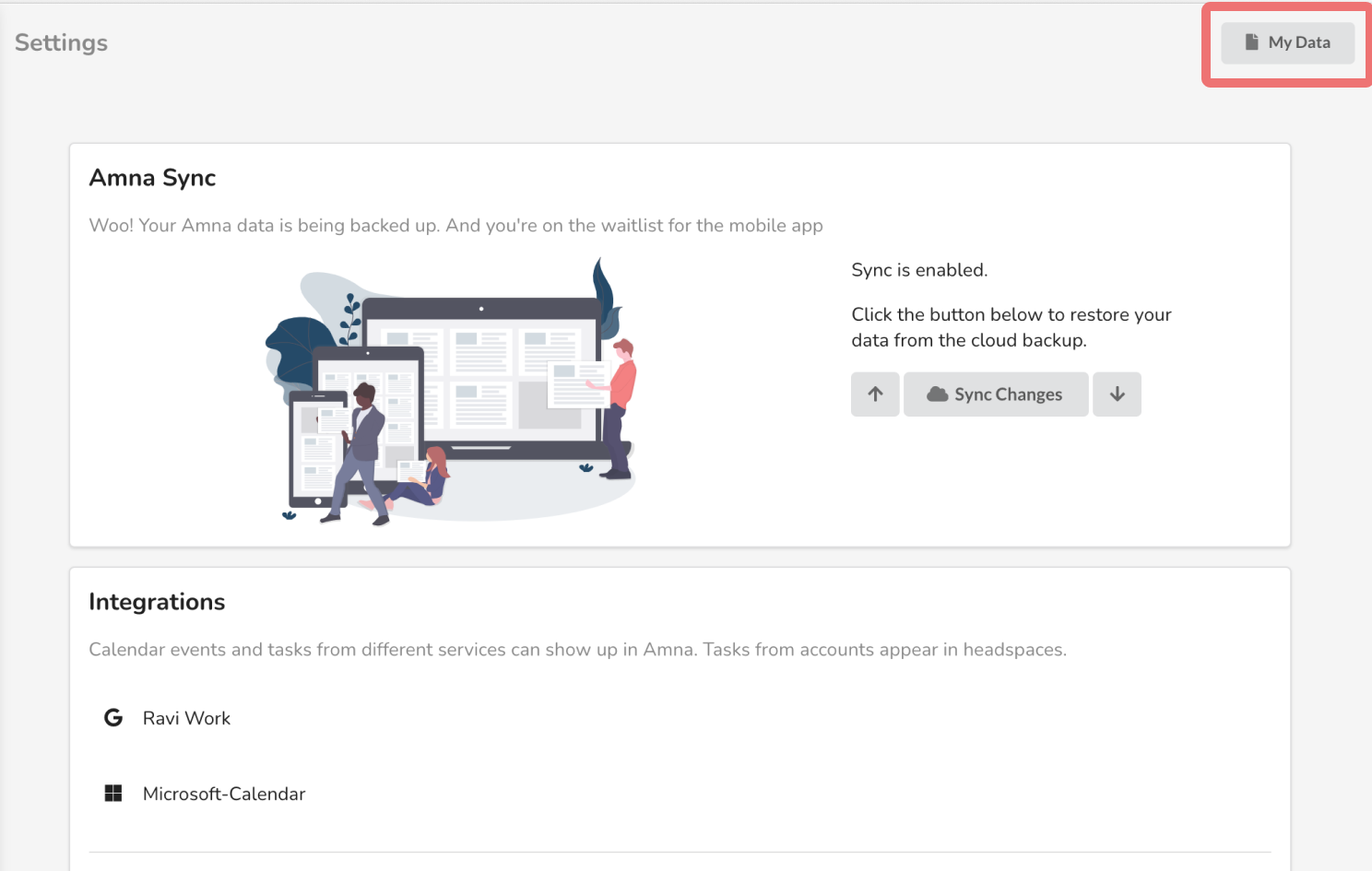
Tap the my data button to see info
If you’re a developer, good news, we’ll push to open source our graph library in the future so you can play with the information and do cool things with it.
Syncing Graph Data
Amna Sync is a our paid plan to automatically back up graph data. Hard drives can fail and devices get stolen. We still use the cloud as a reliable backup store.
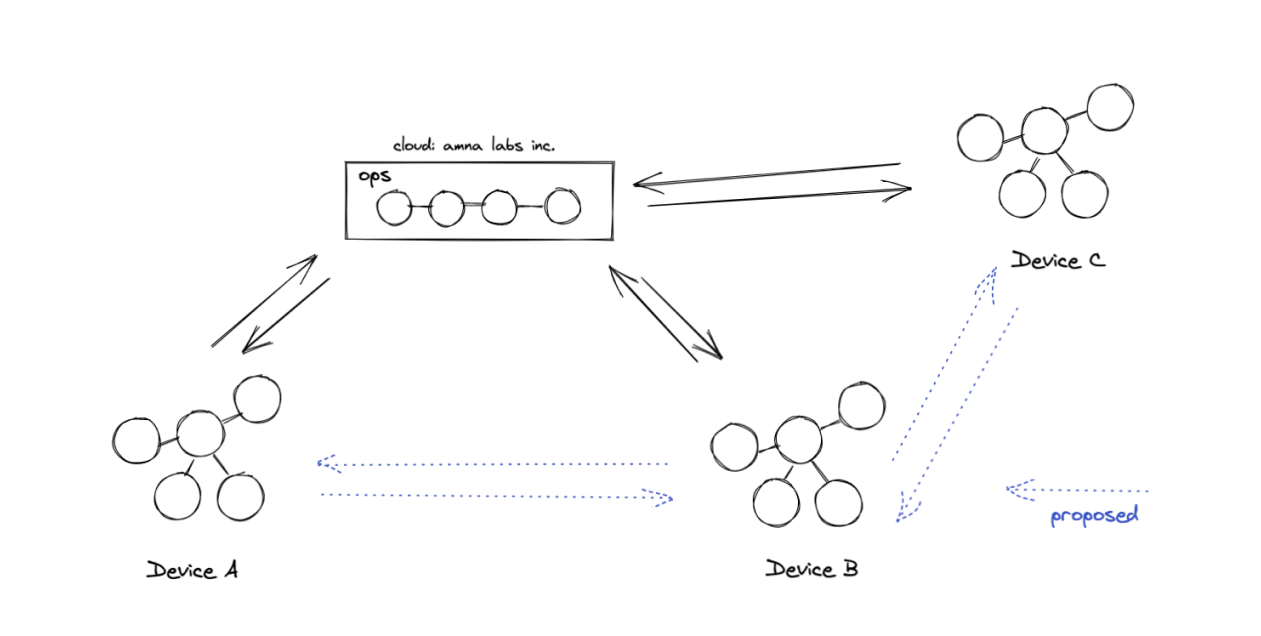
Anma Graph Sync
If you’re a technical geek, Amna Sync works a little bit like git, where we store changes as operations.
Inspired from Excalidraw’s approach, and the fantastic work done with CRDTS, Amna employs a similar process where when syncing graphs using operations.
We believe there is more innovation and simplification to happen in data storage for consumers. (Consider getting in touch if you like this space)
Amna World View
We think of Amna as a digital wallet for your action items from everywhere. You can use it collect items from home, at work, and from the all the commitments across your life and links to the supporting information.
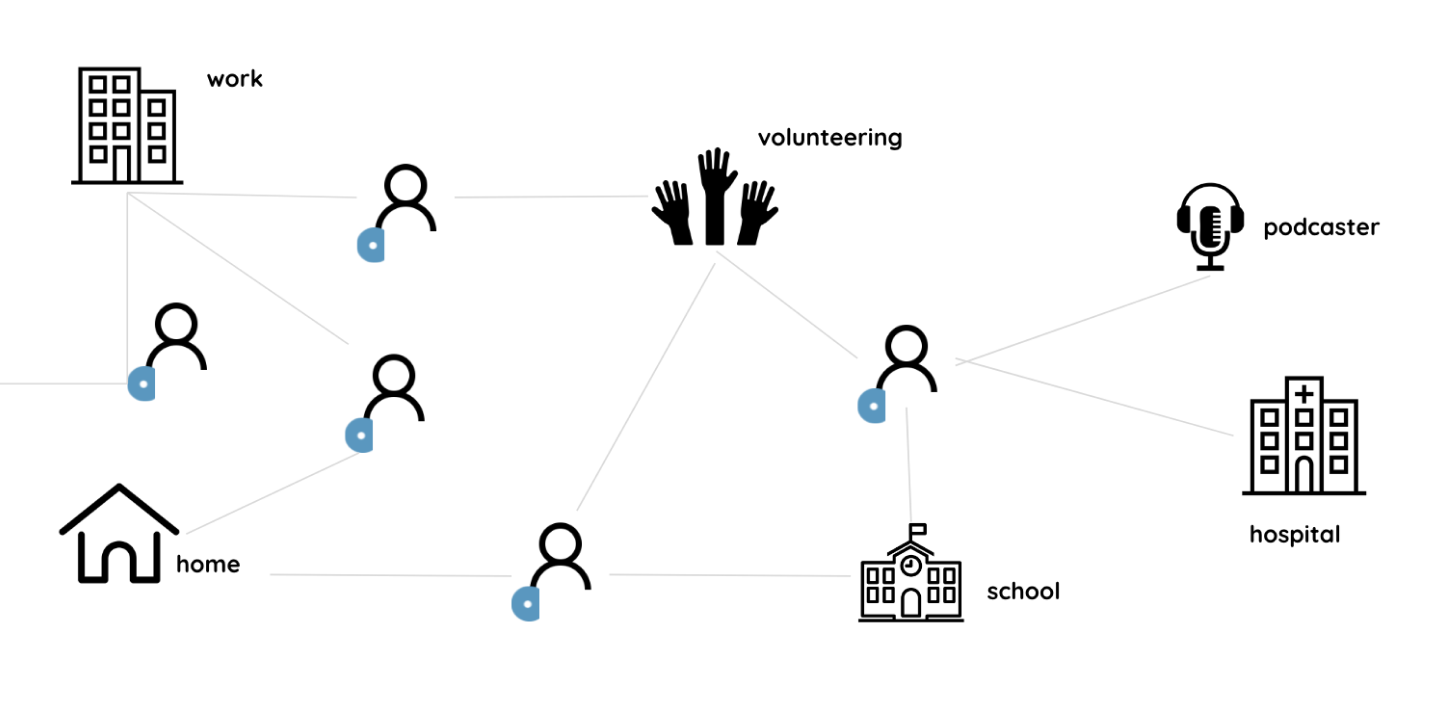
A decentralized world of action items
Keeping data decentralized provides full ownership to consumers. Tasks can freely be exchanged or cloned among people with high ownership. Information has a way to be crowdsourced. Information can be transferred to places as processed groups, rather than small fragmented links.